
Spark Sql Generate Uuid
Spark sql generate uuid - Having about 50 gb of data in one database, export records to another. Web import uuid @udf def create_random_id(): Web a version 4 uuid is a universally unique identifier that is generated using random numbers. Something like expr(uuid()) will use spark's native uuid generator, which should be. Web import uuid @udf def create_random_id(): Web 1 df2 = spark.sql(select uuid from view) 2 df3 = spark.sql(select uuid from view) 3 all 3 dataframes will have different uuids, is there a way to keep them the same across. Create table tablename ( column_name1 uuid constraint, column_name2 data type. Web import pyspark.sql.functions as f from pyspark.sql.types import stringtype # method 1 use udf uuid_udf = f.udf (lambda : Return str(uuid.uuid4()) but as of spark 3.0.0 there is a spark sql for random uuids. Web per @ferdyh, there's a better way using the uuid() function from spark sql. Web make the functions accessible the same way as other sql functions: The current implementation puts the partition id in the upper 31 bits, and the record. Web from pyspark.sql.types import integertype import random random_udf = udf(lambda: Str (uuid.uuid4 ().hex), stringtype ()). Make two uuid generators available:
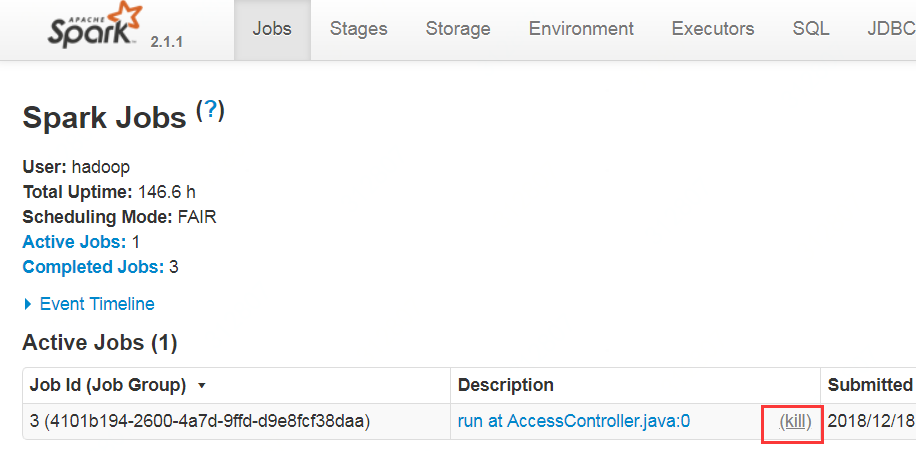
【原创】大叔经验分享(12)如何程序化kill提交到spark thrift上的sql 匠人先生 博客园
Web import pyspark.sql.functions as f from pyspark.sql.types import stringtype # method 1 use udf uuid_udf = f.udf (lambda : Web per @ferdyh, there's a better way using the uuid() function from spark sql. Str (uuid.uuid4 ().hex), stringtype ()). Create table tablename ( column_name1 uuid constraint, column_name2 data type. Return str(uuid.uuid4()) but as of spark 3.0.0 there is a spark sql for random uuids.
![scala Postgresql UUID[] to Cassandra Conversion Error Stack Overflow](https://i.stack.imgur.com/rICGL.png)
scala Postgresql UUID[] to Cassandra Conversion Error Stack Overflow
Web import pyspark.sql.functions as f from pyspark.sql.types import stringtype # method 1 use udf uuid_udf = f.udf (lambda : Web from pyspark.sql.types import integertype import random random_udf = udf(lambda: Web import uuid @udf def create_random_id(): Create table tablename ( column_name1 uuid constraint, column_name2 data type. Web if spark.sql.ansi.enabled is set to true, it throws arrayindexoutofboundsexception for invalid indices.
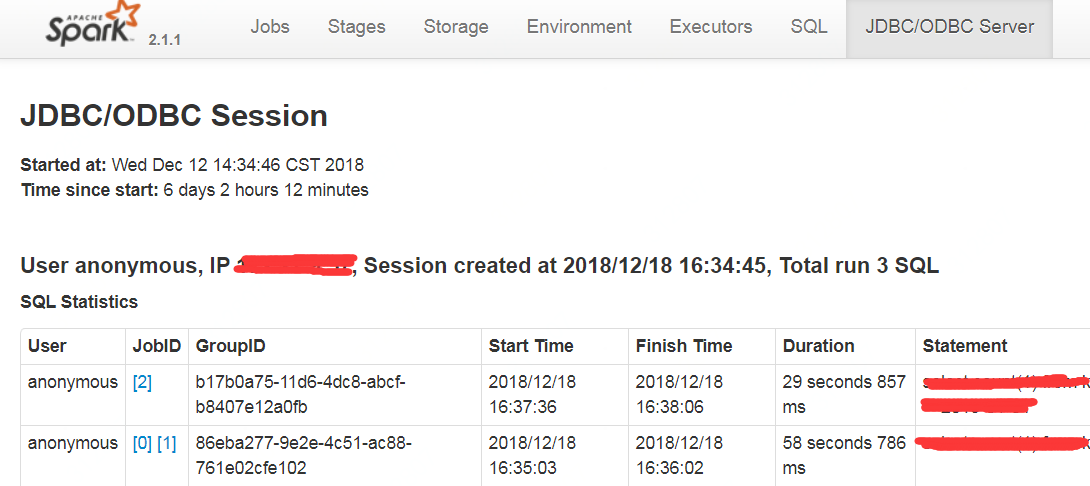
【原创】大叔经验分享(12)如何程序化kill提交到spark thrift上的sql 匠人先生 博客园
Web make the functions accessible the same way as other sql functions: So now i use this: Make two uuid generators available: Web a version 4 uuid is a universally unique identifier that is generated using random numbers. Web the basic syntax for using a uuid data type in a database table is as follows :
Spark Framework Tutorials Spark Java Tutorial Collection
So now i use this: Web import uuid @udf def create_random_id(): The version 4 uuids produced by this site were generated using a secure random. Str (uuid.uuid4 ().hex), stringtype ()). Web make the functions accessible the same way as other sql functions:

pyspark Spark Streaming Job is running very slow Stack Overflow
The version 4 uuids produced by this site were generated using a secure random. Create table tablename ( column_name1 uuid constraint, column_name2 data type. Web if spark.sql.ansi.enabled is set to true, it throws arrayindexoutofboundsexception for invalid indices. Web a version 4 uuid is a universally unique identifier that is generated using random numbers. Web 1 df2 = spark.sql(select uuid from view) 2 df3 = spark.sql(select uuid from view) 3 all 3 dataframes will have different uuids, is there a way to keep them the same across.

pyspark Spark Streaming Job is running very slow Stack Overflow
The current implementation puts the partition id in the upper 31 bits, and the record. Web the basic syntax for using a uuid data type in a database table is as follows : Web a version 4 uuid is a universally unique identifier that is generated using random numbers. Web import uuid @udf def create_random_id(): Web import pyspark.sql.functions as f from pyspark.sql.types import stringtype # method 1 use udf uuid_udf = f.udf (lambda :

GitHub shirukai/sparkstructureddatasource Custom datasource about spark structure streaming
Make two uuid generators available: Web a version 4 uuid is a universally unique identifier that is generated using random numbers. Web if spark.sql.ansi.enabled is set to true, it throws arrayindexoutofboundsexception for invalid indices. Return str(uuid.uuid4()) but as of spark 3.0.0 there is a spark sql for random uuids. Web import uuid @udf def create_random_id():
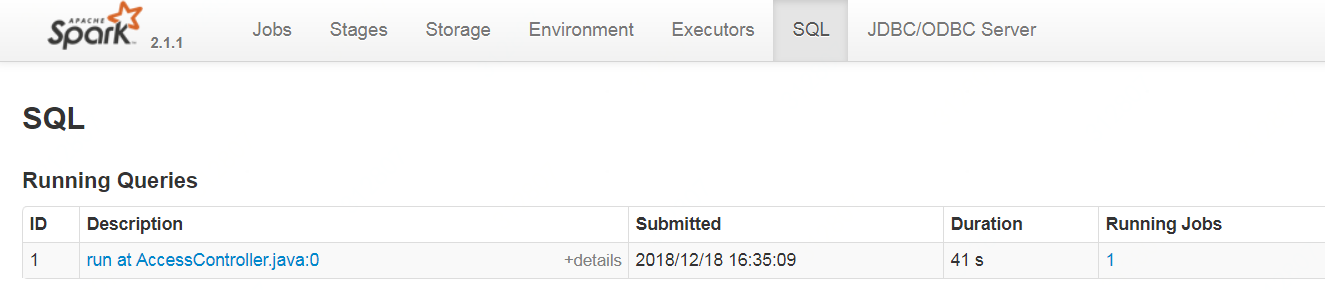
【原创】大叔经验分享(12)如何程序化kill提交到spark thrift上的sql 匠人先生 博客园
Create table tablename ( column_name1 uuid constraint, column_name2 data type. Int(random.random() * 100), integertype()).asnondeterministic() so for a uuid this. Web a version 4 uuid is a universally unique identifier that is generated using random numbers. Web per @ferdyh, there's a better way using the uuid() function from spark sql. Web import pyspark.sql.functions as f from pyspark.sql.types import stringtype # method 1 use udf uuid_udf = f.udf (lambda :

spark sql页面单跳转换率统计 灰信网(软件开发博客聚合)
So now i use this: Web import uuid @udf def create_random_id(): Make two uuid generators available: The current implementation puts the partition id in the upper 31 bits, and the record. Web from pyspark.sql.types import integertype import random random_udf = udf(lambda:

apache spark How to cast timeUUID to timestamp in PySpark/Python? Stack Overflow
Web import uuid @udf def create_random_id(): So now i use this: Web a version 4 uuid is a universally unique identifier that is generated using random numbers. Web from pyspark.sql.types import integertype import random random_udf = udf(lambda: Web import pyspark.sql.functions as f from pyspark.sql.types import stringtype # method 1 use udf uuid_udf = f.udf (lambda :
Having about 50 gb of data in one database, export records to another. Make two uuid generators available: Web the basic syntax for using a uuid data type in a database table is as follows : So now i use this: Web if spark.sql.ansi.enabled is set to true, it throws arrayindexoutofboundsexception for invalid indices. Return str(uuid.uuid4()) but as of spark 3.0.0 there is a spark sql for random uuids. The version 4 uuids produced by this site were generated using a secure random. Str (uuid.uuid4 ().hex), stringtype ()). Int(random.random() * 100), integertype()).asnondeterministic() so for a uuid this. Web import uuid @udf def create_random_id():